

3 Common Unicode Issues and How to Fix them
Unicode Issues when Manipulating String and Modules


Usually, it's not hard for us to do text or string manipulation. We can read from a file, write to a file and compare and order strings. Only At times, it's not so straightforward because there are some potential pitfalls.
SyntaxError When Loading Modules with Unexpected Encoding
Every one of us Python enthusiasts has probably encountered this at least once in his programming or engineering career: SyntaxError: Non-UTF-8 code.
If you load a .py module containing non UTF-8 data with no encoding declaration you will get the error above, a likely scenario is opening a .py file created on Windows with cp1252 codec.
To solve this we just add a magic coding comment at the top of the file!
# coding: cp1252
print('Olá, Mundo!')
# Olá, Mundo!
Text File Issues
The best practice for handling text I/O is the Unicode sandwich. It's important to decode bytes to str as soon as you can when you're opening a file for reading. The middle layer of the sandwich is the program's business logic, which involves strictly manipulating text with str objects.
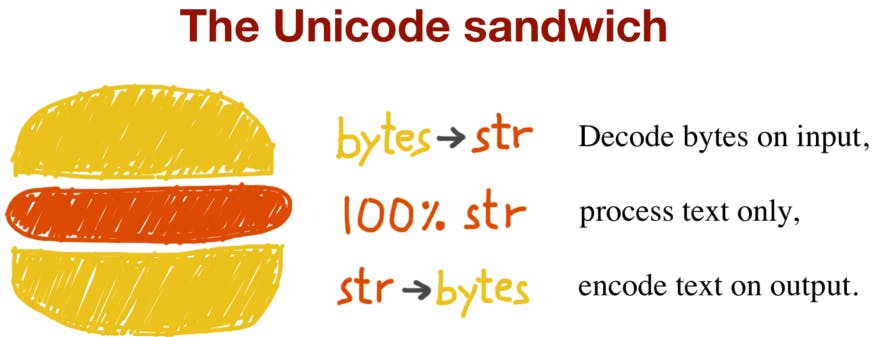
Sometimes when decoding we will encounter an error, it's the UnicodeEncodeError Exception! This Happens because we did not specify the encoding argument when opening the file.
Python by default calls locale.getpreferredencoding() when it doesn't find the encoding argument in your open file call. The preferred encoding is different from one platform to another, in Windows, it's the cp1252 encoding while in Linux it's the UTF-8 and this raises the exception.
Hence the solution would be to always provide the encoding argument!
fp = open('cafe.txt', 'w', encoding='utf_8')
print(fp)
# <_io.TextIOWrapper name='cafe.txt' mode='w' encoding='utf_8'>
fp2 = open('cafe.txt')
print(fp2)
# <_io.TextIOWrapper name='cafe.txt' mode='r' encoding='cp1252'>
print(fp2.encoding)
# cp1252
Sorting Text Issue
Python sorts strings by comparing the code points. Unfortunately, this produces unacceptable results for anyone who uses non-ASCII characters, more specifically, different locales have different sorting rules.
The standard way to sort non-ASCII text in Python is to use the locale.strxfrm function which, according to the locale module docs, transforms a string to one that can be used in locale-aware comparisons.
import locale
# set locale to Portuguese with UTF-8 encoding
my_locale = locale.setlocale(locale.LC_COLLATE, 'pt_BR.UTF-8')
fruits = ['caju', 'atemoia', 'cajá', 'açaí', 'acerola']
sorted_fruits = sorted(fruits, key=locale.strxfrm)
print(sorted_fruits)
# ['açaí', 'acerola', 'atemoia', 'cajá', 'caju']
There are a few caveats though:
The locale must be installed on the OS, otherwise
setlocaleraises a
locale.Error: unsupported locale setting exception.The locale must be correctly implemented by the makers of the OS, which is not always the case.
Locale settings are global, calling
setlocaleis global. Your application or framework should set the locale when the process starts, and should not change it afterward.
How to Properly Sort Text?
The simplest solution for us is to use a Library, as always.
Pyuca is a pure Python implementation of the Unicode Collation Algorithm (UCA).
The UCA details how to compare two Unicode strings while remaining conformant to the requirements of the Unicode Standard.
import pyuca
coll = pyuca.Collator()
fruits = ['caju', 'atemoia', 'cajá', 'açaí', 'acerola']
sorted_fruits = sorted(fruits, key=coll.sort_key)
print(sorted_fruits)
# ['açaí', 'acerola', 'atemoia', 'cajá', 'caju']
This is simple and works on GNU/Linux, macOS, and Windows.
Conclusion
All sorts of bugs can creep their way into our code and the encoding bugs are no joke! A Unicode Exception could break the app and it's better to catch it as early as possible.
Further Reading
The full article is on my Blog where I get into more details.
The official “Unicode HOWTO” in the Python docs
Chapter 2, “Strings and Text” of the book: The Python Cookbook, 3rd ed
Nick Coghlan’s “Python Notes” blog has two posts very relevant to this chapter: “Python 3 and ASCII Compatible Binary Protocols” and “Processing Text Files in Python 3”. Highly recommended.
List of encodings supported in Python.
The book Unicode Explained by Jukka K. Korpel.
The book Programming with Unicode.
Chapter 4 of the book Fluent Python.